An introduction to measures of central tendency: mean, mode and median. Calculating these values will help you understand better your data: is it normally distributed or skewed? Which is the value that appears most frequently?
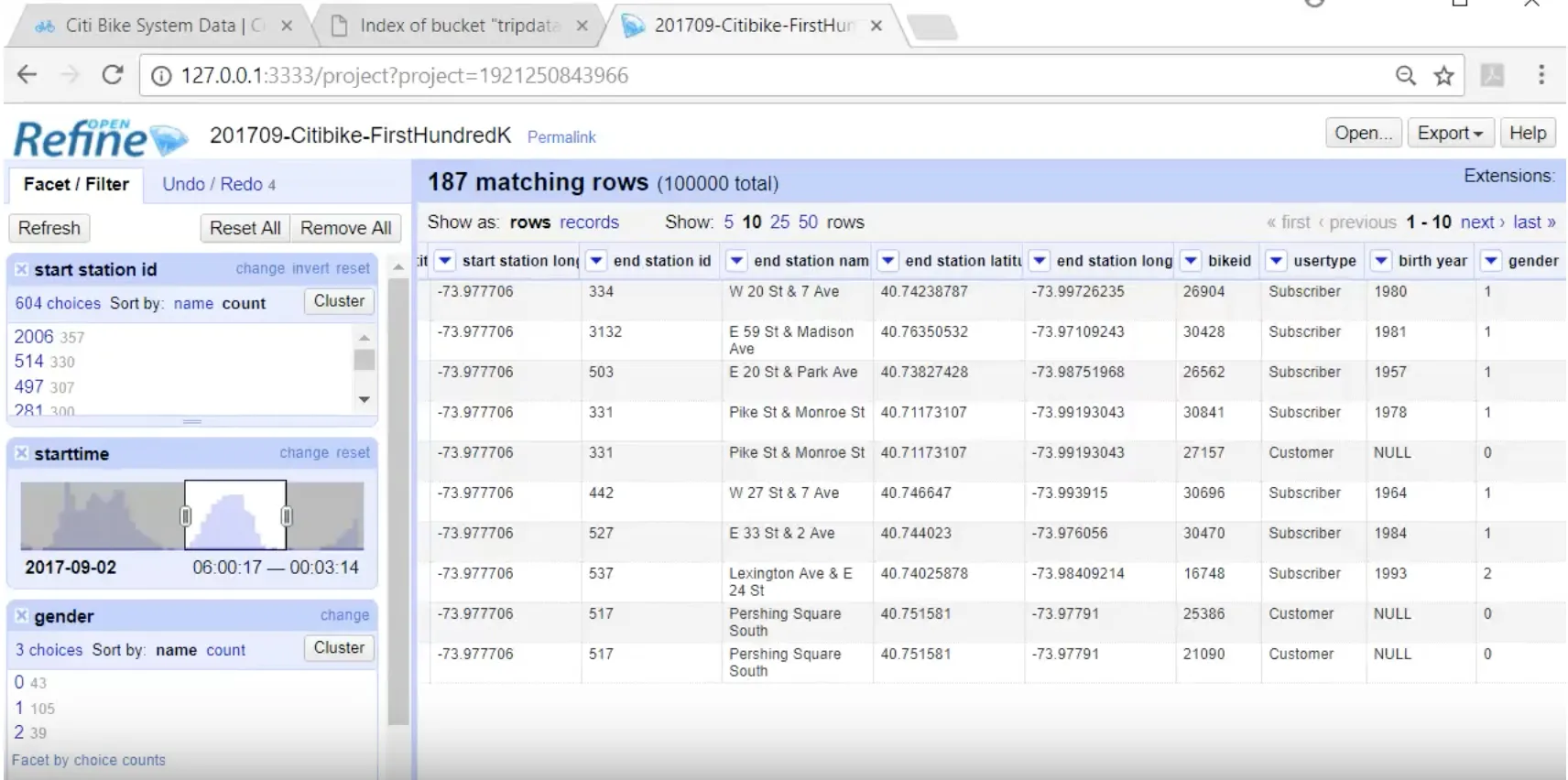
An introduction to OpenRefine, an open source tool for manipulating large, messy data sets. This tutorial explores facets and transformations to interview and analyze data. Video 1 of 3.
Slides with a brief introduction to Regular Expressions, how they work, some grammar and examples. RegEx are useful to search for and match a pattern in your data and clean it up from there.
Learn how to edit data massively using the clustering feature. See how to apply/extract commands to step backwards and forwards through your work, as well as apply it to new or revised data sets. Video 3 of 3.
An overview class on what to count, how to “interview the data,” statistical models, the uses of multi-variable regression in journalism, and correlation vs. causation.
A class on visualization (built upon design principles from user experience considerations, graphic design, and the study of the human visual system) and social network analysis in journalism
The ProPublica guide offers useful tips to make sure you're interviewing a data set comprehensively: create work logs, pull random samples, duplicate your work, show finding early, etc.
A step-by-step guide to analyzing data with Python and the Jupyter Notebook: create filters, merge cells, add values, sort or group by specified conditions, all with pandas, an open-source library.
A visualization and analysis tool designed for sets of documents, from dozens to millions of pages of material. Originally built for investigative journalists, it’s also used for legal work, training machine learning models, and research of all types.
A Python library built to process large amounts of text. Whether you’re analyzing Congressional bills, Twitter outrages or Shakespearean plays, NLTK has you covered.
A Python package for machine learning and data analysis. It’s the Swiss Army knife of data science: it covers classification, regression, clustering, dimensionality reduction, and so much more.